Mysql索引
本文基于Innodb存储引擎编写,图源+总结自《mysql是怎样运行的》
简介
MySQL索引是MySQL数据库中的一种数据结构,它可以帮助快速查询数据。它类似于书的索引,可以让您快速找到特定的数据行,而无需遍历整个数据表。
索引是通过在一个或多个列上创建一个数据结构来实现的。当查询需要使用索引的列时,MySQL会使用索引的数据结构来快速定位和检索相应的数据行。这种方式比全表扫描要快得多,特别是在大型数据表中查询数据时,索引的性能优势非常明显。
B+树索引
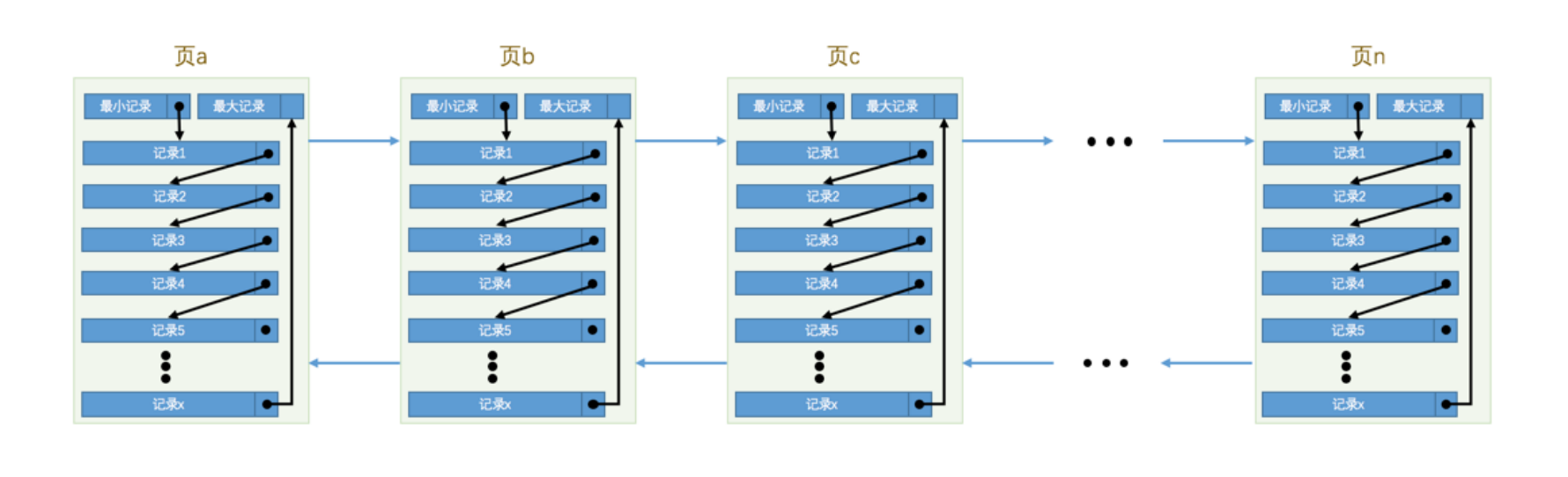
mysql通过数据页进行存储数据,如下图结构,每个数据页之间的结构是双向链表,单个数据页内的记录是通过单向链接根据主键从小到大串连
每个数据页会为里面的记录生成页目录(槽组成页目录)
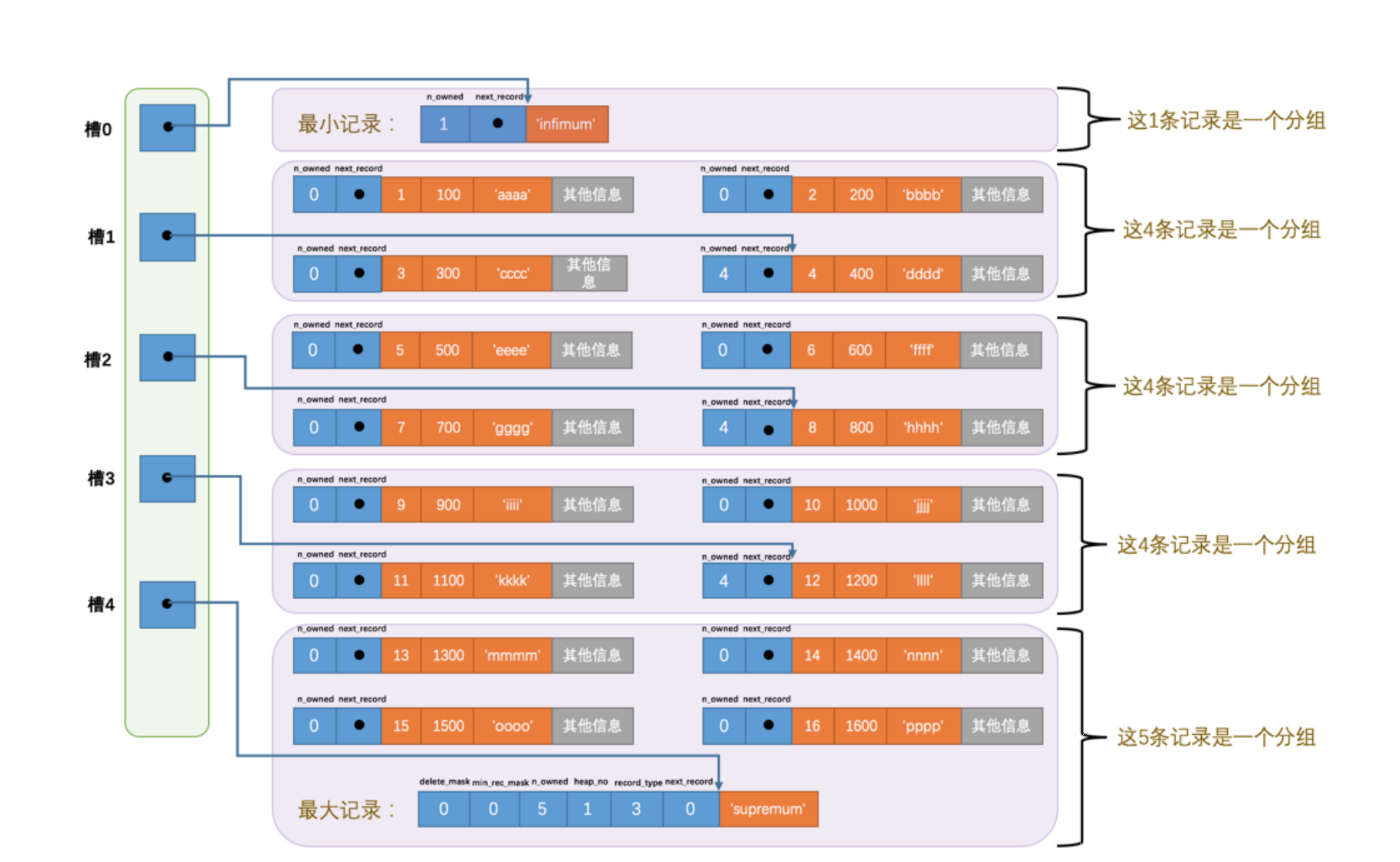
如果是根据主键(有序存储进数据页)查找是通过二分快速定位然后遍历槽(4-8条记录组合一个槽)内记录会比较快。但是如果不是主键的字段(且不是索引)这种情况下只能按主键顺序把每个数据页从 最小记录 开始依次遍历单链表中的每条记录。
Innodb使用 目录项纪录 来实现索引,目录项纪录里只存储主键+数据页号,目录项纪录还有更顶层的目录项纪录,直至根节点,如下图
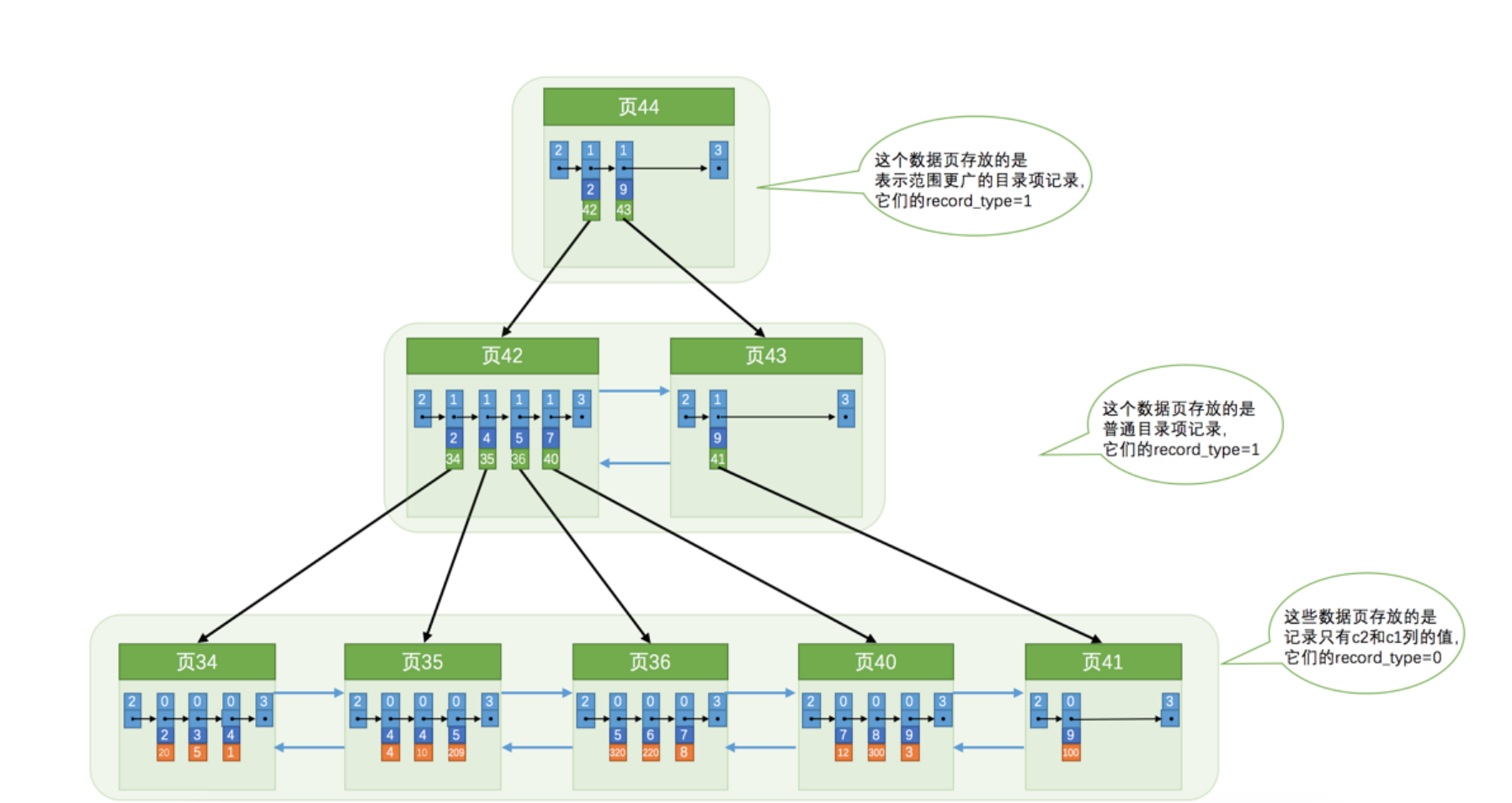
叶子结点存放用户记录,非叶子结点(内结点)存放目录项
聚簇索引
聚簇索引根据主键值的大小进行记录和页的排序,目录项存储的是主键值和数据页号,叶子结点记录的是完整的用户记录。不需要显式的使用Index去创建,Innodb会为我们自动创建。
非叶子结点(目录项记录):主键 - 数据页号
叶子结点(索引记录):主键 - 完整用户记录
二级索引
二级索引根据索引键值的大小进行记录和页的排序,非叶子结点记录索引键值和数据页号,叶子结点只记录索引键值和主键值。二级索引查询到主键后需要执行回表操作获取完整记录。(再开了一个b+树)
非叶子结点(目录项记录):索引列 - 数据页号
叶子结点(索引记录):索引列 - 主键
联合索引
联合索引是按照定义的索引列顺序排序,对于相同的索引列,再按照其索引键值的大小进行排序。也就是说,在索引建立之时,定义的索引列顺序就对应了索引的排序方式,按照它们定义的顺序排序,以达到最优的查询效率。
对于非叶子结点,它们按照索引列的顺序记录着子结点的索引键值和数据页号,索引键值用于指示要查找的数据应该落在哪个子结点中,数据页号则用于指示存储该子结点中数据的数据页。
对于叶子结点,它们也按照索引列的顺序记录着索引键值和主键值,索引键值用于查询操作中定位到叶子结点,而主键值则用于获取完整的数据行。
联合索引遵循最左前缀集合。
非叶子结点(目录项记录):A索引列 - B索引列 - 数据页号
叶子结点(索引记录):A索引列 - B索引列 - 主键
其他
字符串索引原理
在B-tree索引中,MySQL将每个字符串值都分解成一组前缀,然后将这些前缀作为索引的键值。这些前缀可以是固定长度的,也可以是可变长度的,具体取决于索引定义的长度。
例如,如果我们在一个名为mytable的表的name列上创建了一个长度为10的索引,那么MySQL将对每个name值提取前10个字符,并将其存储在索引树中。查询时,MySQL可以使用这个索引快速查找匹配的记录。
然而,需要注意的是,在创建索引时需要权衡索引长度和查询效率。如果索引长度过长,那么会导致索引树变得更大,更慢,甚至会影响到查询性能。因此,我们需要根据具体情况来确定索引长度,以平衡查询效率和存储空间的利用率。
查询时MySQL 会将字符串按照字符集的排序规则进行比较